
2025年,一个新的概念诞生——数字中文,基于以往多年中国实践,因应当前世界人工智能大势,开启今后一个时期序幕。从年初的1月8日,教育部、国家语委、中央网信办印发《关于加强数字中文建设 推进语言文字信息化发展的意见》,首次提出“数字中文”概念;到年底的12月27日,第十四届全国人民代表大会常务委员会第十九次会议表决通过新修订的《中华人民共和国国家通用语言文字法》,明确规定“推进国家通用语言文字的信息化、数字化、智能化建设”。2025年注定是语言文字信息化发展加速推进,数字中文建设稳步开局的重要年份。回望过去的一年,可以看到一条从构想到落地的足迹,看到一幅挑战与成果交织的图景。国家语言资源监测与研究中心梳理了一年的数据,推出2025年度中国语言文字信息化和数字中文建设十大新闻。
教育部联合中央网信办印发加强数字中文建设的文件
——为语言文字信息化发展指明未来方向
点击查看原文
1月8日,教育部、国家语委、中央网信办印发《关于加强数字中文建设 推进语言文字信息化发展的意见》,首次提出“数字中文”概念。《意见》分段明确到2027年和2035年的发展目标,提出完善规范标准体系、健全资源服务体系、建强人才培养体系、构建协同创新体系、强化安全保障体系等建设任务;要求实施数字中文服务教育发展、助力科技创新、赋能文化传承、推动产业升级、促进社会进步等赋能行动。3月31日,教育部召开新闻发布会,提出以加快数字中文建设为重点,全方位释放语言文字的数据要素价值、全环节发挥语言文字的资源功能作用、全领域推进语言文字服务经济社会发展,助力提升中文在全球数字空间、网络空间和人工智能应用场景中的使用占比、价值引领和文化贡献。6月8日,《光明日报》发表《加强数字中文建设,全方位释放中文要素价值》文章,精准阐释“数字中文”内涵,系统构建数字中文建设政策体系和研究体系框架。
加强数字中文建设纳入国家语言能力建设改革试点
——为加快推进数字中文建设探路

第四届“中文+物流与供应链职业技能”国际赛暨首届东盟国家高校邀请赛在广西发布(图源:广西壮族自治区教育厅 )
3月27日,中央教育工作领导小组围绕深入实施《教育强国建设规划纲要(2024—2035年)》和三年行动计划,部署启动三年行动计划综合改革试点,设立国家语言能力建设改革试点任务,将加强数字中文建设作为一个突出重点,在多个省份多所学校深入推进,标志着国家数字中文建设全面启动。各省份制定聚焦数字中文建设的语言文字信息化工作方案,“一省一策”推进数字赋能行动,实施特色项目。北京举办多语种Al语音翻译大赛,系统评估市场主流同传产品效果。浙江、上海积极发挥辖区内高校、国家语言文字科研机构等作用,召开数字中文建设研讨会,带动多方面参与。河南建成中华汉字文化园,建设甲骨文语料库,开发甲骨文智能体。广西以“中文+物流与供应链职业技能”国际赛为载体,收集东盟多语种使用案例、行业术语等资源。广东组织开发语言服务大语言模型,发布粤方言语料库平台。湖南加快推进中国语言资源博物馆建设。
中缅英互译系统入选2025世界人工智能大会案例集
——中国大语言模型技术首次用于国际救援

基于DeepSeek7小时研发的中缅英多语种互译应急服务系统投入使用(图源:玉渊潭天)
3月28日,缅甸发生7.9级强震,中国政府第一时间启动应急机制,救援队伍火速集结,赶赴震区展开救援。为积极响应我驻缅使馆和中国救援队发回国内的需求,教育部、国家语委、应急管理部指导设在北京语言大学的国家应急语言服务团秘书处“把后方当前方”,基于DeepSeek7小时研发中缅英多语种互译应急服务系统,在救援黄金70小时服务700多人次求援语言需求,用“小时级响应”重新定义国际救援,中国技术、大国担当、技术赋能和语言应急获国内外媒体和民众高度关注认可。7月,该案例入选2025世界人工智能大会《中国智·惠世界(2025)》案例集,相关话题阅读量超1亿次。
国家关键语料数据基础设施建设提速
——首开区域高校共建共享智能化语料库先例
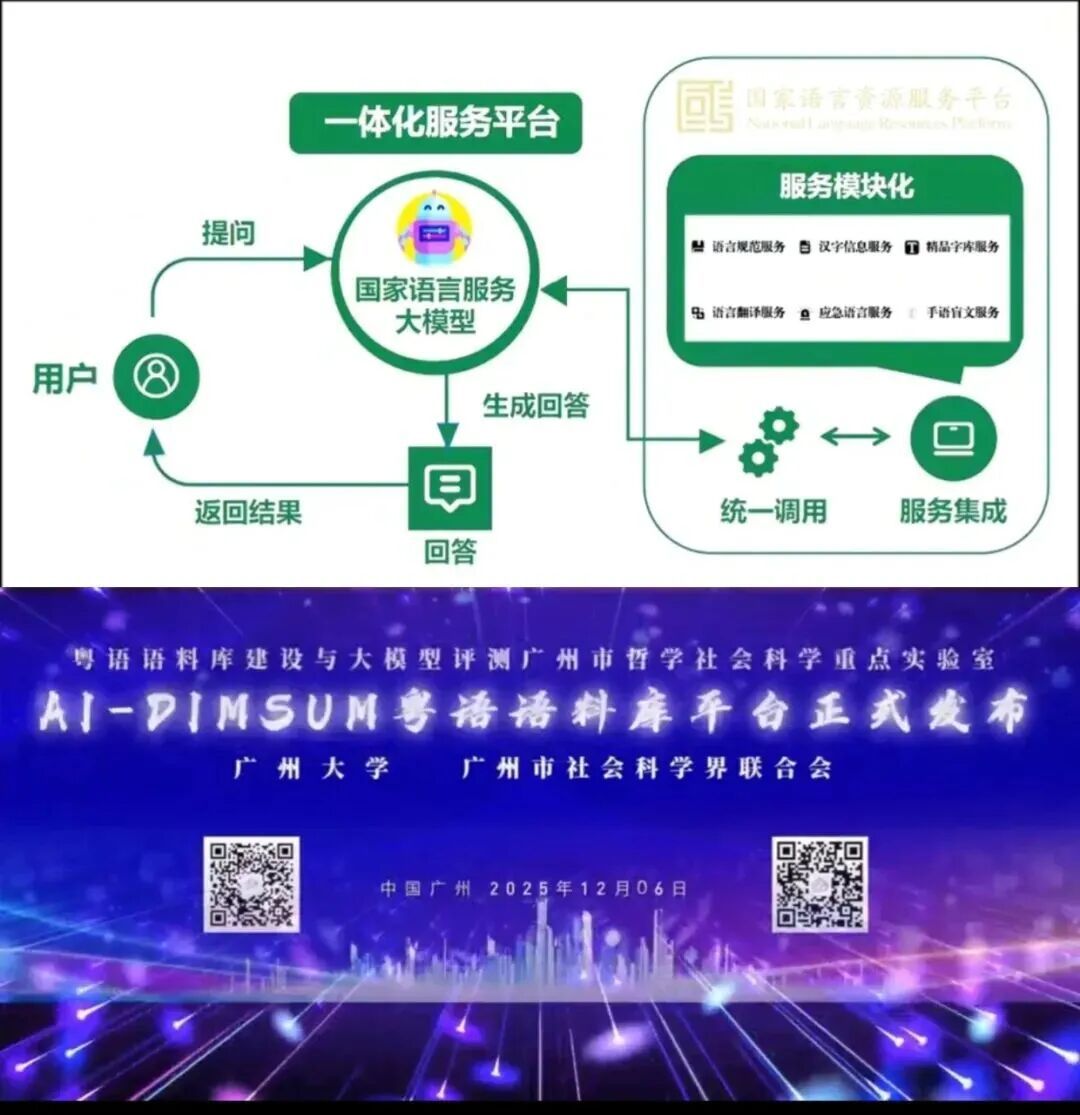
12月6日,第十届语言服务高级论坛暨2025年度国家应急语言服务团学术年会在广州大学举行,语言服务大语言模型正式上线。该大语言模型由香港科技大学(广州)团队联合粤港澳大湾区相关高校共同研发,集成国家语言资源服务平台的各类语言资源,构建服务可集成、知识可溯源的一体化大语言模型,有效支撑国家语言服务体系的智能化建设。年初,《教育部国家语委中央网信办关于加强数字中文建设推进语言文字信息化发展的意见》明确提出“推进中文数字化与数据中文化”。新一轮科技革命和产业变革深入发展,数据中文化构筑数字中文发展基础,中文数据资源建设夯实数智时代“新基建”。媒体语料库、教材语料库、海外华语资源库、中国语言资源数据库等持续扩容。丝路语言文化数据库、中国话语翻译传播综合数据平台、AI-DimSum多模态粤方言语料库等推进建设。
“AI太炎”古汉语大模型迭代升级
——支撑传统语言文化整理、研究与传承
北京师范大学科研团队研发的古汉语大语言模型“AI太炎3.0”亮相第七届教博会(图源:北京师范大学公众号)
12月6日,第十届语言服务高级论坛暨2025年度国家应急语言服务团学术年会在广州大学举行,语言服务大语言模型正式上线。该大语言模型由香港科技大学(广州)团队联合粤港澳大湾区相关高校共同研发,集成国家语言资源服务平台的各类语言资源,构建服务可集成、知识可溯源的一体化大语言模型,有效支撑国家语言服务体系的智能化建设。年初,《教育部国家语委中央网信办关于加强数字中文建设推进语言文字信息化发展的意见》明确提出“推进中文数字化与数据中文化”。新一轮科技革命和产业变革深入发展,数据中文化构筑数字中文发展基础,中文数据资源建设夯实数智时代“新基建”。媒体语料库、教材语料库、海外华语资源库、中国语言资源数据库等持续扩容。丝路语言文化数据库、中国话语翻译传播综合数据平台、AI-DimSum多模态粤方言语料库等推进建设。
全球首个甲骨文AI智能体在安阳发布
——以智能体方式赋能汉字文明传承传播
全球首个甲骨文智能体在殷墟博物馆发布
10月29日,专为甲骨文研究场景打造的AI智能体“殷契行止”在安阳殷墟博物馆发布。该智能体由安阳师范学院甲骨文信息处理教育部重点实验室联合腾讯SSV数字文化实验室等众多机构共同研发,集成了甲骨单字识别、甲骨单字检索、甲骨单字研究、拓片摹本生成和拓片重见检索五大核心功能,面向大众免费使用。同时构建全球规模最大的甲骨文多模态数据集,包含143万个甲骨文字形数据、1.5万片甲骨多模态数据、3000篇研究文献等。目前,已通过“全球甲骨文数字化回归”项目完成韩、德、法等国甲骨文数据采集,950片流失海外的甲骨通过数字化手段“回归”。
数字中文建设科研项目多点发力
——为数字中文建设提供有组织智力支撑

点击查看原文
7月18日,国家语言文字“十四五”科研规划2025年选题指南正式发布,围绕数字中文建设、语言科技发展等领域,设立重大项目“全球数字空间中文影响力调查与提升研究”、重点项目“语言数据要素驱动产业发展的统计测度与实现路径研究”“面向视听双障人群的触觉手语与手指盲文语料库建设研究”、一般项目“中文数字化进程与‘十五五’期间发展策略研究”等选题,吸引2500多个团队申报。11月28日,国家语言文字科研机构2025年工作会议召开,会议强调,国家语言文字科研机构要坚持战略牵引、AI赋能,发挥语言聚焦高价值领域全局赋能经济社会的功能作用。
多所大学开设“语言科学”新专业
——促进数字科学与语言科学交叉融合
点击查看原文
11月18日,语言学科专业建设研讨会在北京语言大学举行。会议指出,要加强语言人才供需机制研究,支持高等学校语言学科与多学科深度交叉融合发展。会议认为,语言科技人才用人单位以互联网、教育行业为主,核心岗位集中于自然语言处理、内容生成等领域。从供需对接障碍看,要深入推进产教融合、健全评估机制,强化高校培养与企业实践紧密衔接,有效破除“低端人才过剩、高端人才短缺”行业结构性矛盾。前期,已在华中科技大学、江苏师范大学、上海外国语大学、北京语言大学等设立语言科学学科建设与专业人才培养试点,相关学校结合学校特色初步推出课程体系;在北京语言大学开展学生大语言模型素养培养试点,提出学生理解和使用大语言模型应具备的素养框架,推进素养监测和提升。
中国大模型大会(第二届)共话大语言模型创新发展
——推动前沿理论创新与可靠应用落地

中国中文信息学会2025学术年会暨第二届中国大模型大会现场(图源:中国中文信息学会公众号)
10月28日,中国中文信息学会 2025 学术年会暨第二届中国大模型大会召开,吸引来自高校、科研机构及产业界的600余位专家学者参会。大会聚焦“大模型的理论突破、技术前沿、产业落地与生态共建”等,打造立足学术前沿、面向产业应用、引领智能未来的思想盛会。围绕生成式人工智能、知识图谱、具身智能、情感计算、社会媒体处理等前沿热点,邀请大模型与人工智能领域的多位学者作报告,开展深入探讨。大会同期举办13场大模型专题论坛,系统呈现从多模态融合、认知智能到产业落地等最新研究成果与实践探索,展现了中国学术界与产业界在人工智能领域的蓬勃创新活力。
中文要素价值持续释放,数字空间中文能级不断提升
——中文母语国的数据产业规模超过5.8万亿元
10月28日,中国中文信息学会 2025 学术年会暨第二届中国大模型大会召开,吸引来自高校、科研机构及产业界的600余位专家学者参会。大会聚焦“大模型的理论突破、技术前沿、产业落地与生态共建”等,打造立足学术前沿、面向产业应用、引领智能未来的思想盛会。围绕生成式人工智能、知识图谱、具身智能、情感计算、社会媒体处理等前沿热点,邀请大模型与人工智能领域的多位学者作报告,开展深入探讨。大会同期举办13场大模型专题论坛,系统呈现从多模态融合、认知智能到产业落地等最新研究成果与实践探索,展现了中国学术界与产业界在人工智能领域的蓬勃创新活力。
有学者认为,2025年,数字中文建设完成了概念呈现到推进实施的关键一步,在大语言模型技术快速迭代升级、高质量语料数据成为创新应用核心资源的背景下,积极回应了时代变化和社会需求,提出了新的责任使命。数字中文意味着信息化、数字化、智能化全面驱动中文在全领域、全场景、全球化的重构与拓展,是给数字时代赋予中国之心、中文之心。可预见的将来,数字中文建设将成为支撑人工智能技术发展、提升中文全球影响力的核心载体,加速助力提升中文在全球数字空间、网络空间和人工智能应用场景中的使用占比、价值引领和文化贡献。
转发自《语言监测与智能学习》

